
What Is Probabilistic Attribution? (And Every Other iOS 14 Question You Were Afraid to Ask)
The shift to opt-in IDFA tracking means a new way to measure user acquisition. Here’s what you need to know.
This article was originally published on the AlgoLift by Vungle blog in August 2020 by Paul Bowen.
The privacy-centric changes that accompany Apple’s iOS 14.5 are also driving changes to user acquisition measurement. Previously, app developers could use a device’s IDFA data to track user behavior and learn how they interacted with advertising, but moving forward will need the user’s permission to access it.
While mobile app marketers will still be able to track anonymous, aggregated totals, they’ll no longer have access to user-level attribution. Apple’s proposed data-gathering solution for advertisers, SKAdNetwork, uses probabilistic attribution to connect user behavior to specific campaigns. But what is it and how will it impact mobile marketers?
1. What is probabilistic attribution for iOS 14?
Probabilistic attribution is the process of assigning campaign membership probabilities to a user based on attributes and behavior of that user. Unless a user shares their IDFA on iOS 14, we can’t assign a 100% probability that a specific campaign drove an install. Instead, we use a set of probabilities that the install was driven by one or more campaigns.
In the context of iOS 14, the following user-level data sets are available:
- Anonymous user-level in-app data: Customer-generated user ID, revenue data, in-app events
- SKAdNetwork data: Postbacks containing campaign ID, source app ID, Conversion Value (more about this later)
- Deterministic attribution from MMPs: Opt-in iOS 14 users and users identified by other means within Apple’s terms of service
- Ad network reporting data: campaign ID, impressions, spend
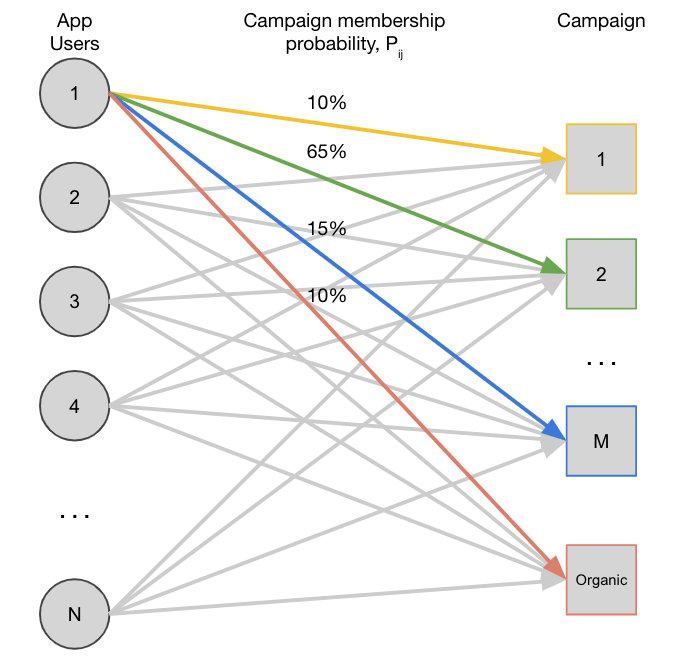
Figure 2 — An example distribution of an app user over multiple user acquisition campaigns based on probabilistic attribution.
Probabilistic attribution doesn’t use any personally identifiable information about a user, as by definition that would allow for matching of an install to a campaign. For this reason, and in the case of iOS 14, the data used shouldn’t use IP address (more about this later).
2. What does iOS 14 mean for measurement of user acquisition campaigns?
At a high level, Apple made several privacy-centric announcements with iOS 14 with respect to the measurement of user acquisition:
- To access the device “identifier For advertisers” (IDFA), an app developer would need permission from the end-user through Apple’s App Tracking Transparency (ATT) prompt in every mobile application used by that device
- Where users didn’t give permission to access their IDFA through the ATT pop-up, Apple has made available SKAdNetwork, an attribution solution for iOS 14+ that has the following ramifications for measurement of performance marketing on iOS:
- User-level campaign and channel attribution data will not be available: Network, campaign, geo, creative, source app, and placement will all be missing from the attribution data at the user level. Only anonymous data such as campaign-level installs, source app, and some down-funnel events will be reported.
- Campaign performance data for down-funnel events will be restricted: Revenue and in-app events will be significantly limited. This move is intended to ensure no back-engineering of the SKAdNetwork solution which would allow advertisers to directly attribute a user to a campaign.
This announcement completely disrupts mobile measurement. Mobile app marketers will no longer be able to attribute app installs to a channel or campaign and will thus not be able to track ROAS at the channel or campaign level. The current, common practice of adjusting campaign bids and budgets based on D7 ROAS or cohort ROAS curves at the channel or campaign level will no longer be easily accessible for advertisers.
Related Article: Why LTV Is Essential for UA, and D7 ROAS Should Be Retired
3. What is the App Tracking Transparency (ATT) prompt?
ATT is a pop-up called by the mobile app or mobile game developer when they wish to gain access to the device IDFA.
![]()
Once the user allows tracking on this pop-up, Apple will enable access within this application to the device IDFA. This can then be used by developers for user acquisition, retargeting, and ad monetization purposes.
Go Deeper: What Is App Tracking Transparency (ATT) and How Does It Affect Mobile Marketing?
4. What is deterministic attribution?
Deterministic attribution is the exact matching of an app install to an advertising campaign at the user level. When an app install is deterministically attributed to a campaign, there’s an assumed 100% probability that the install campaign came from a specific campaign.
From the Wikipedia definition:
“In mathematics, computer science, and physics, a deterministic system is a system in which no randomness is involved in the development of future states of the system. A deterministic model will thus always produce the same output from a given starting condition or initial state.”
Mobile measurement partners (MMPs) are able to assign 100% probability because the IDFA of a user clicking (or viewing) on an ad is exactly the same as the IDFA sent by the MMP SDK when the user opens the app after the install. MMPs use data engineering efforts to ensure that the receipt from the advertised app of the install event falls within the lookback window, and match back that install event to the advertising campaign that delivered the last click or view on the ad. The lookback window is a period of time after a click where the campaign that drove the install will get credit for its delivery.
5. What is SKAdNetwork’s “Conversion Value”?
Conversion Value is provided by Apple within the SKAdNetwork framework to power probabilistic attribution. To protect user privacy, Apple restricted the amount of post-install data that could be reported against an SKAdNetwork campaign.
The following points are true about Conversion Value:
- Conversion Value is a single value and should be a proxy for LTV
- Conversion Value isn’t reported against a specific install ID and is therefore anonymous
- Conversion Value is reported against a campaign ID
- Conversion Value should be sent by the app to Apple once the app developer has collected enough information about an app install to predict the LTV
- Conversion Value can only be sent once to Apple
Examples of uses for Conversion Value:
- Revenue: Reports the revenue generated by the user within the app
- Retention: Reports the retention rate of the user. For this the user needs to open the app over multiple days.
- In-app events: Reports a series of in-app events that the user completed
- Predicted LTV: Reports the predicted LTV (pLTV) for the user based on revenue, retention, and in-app event (engagement)
We can see from these examples the optimal use of Conversion Value is to use predicted LTV as it encompasses all other possible uses for Conversion Value.
6. What is the “6-bit value” associated with Conversion Value?
A 6-bit value is a series of 6 0’s or 1’s that make up the Conversion Value. Whether these bits are turned off (0) or on (1) can help describe a state, or how something exists. An example would be 001000. A 6-bit value has 2^6 (=2*2*2*2*2*2) different combinations, or 64 ways it can be represented (as each of the 6 bits can be 0 or 1 at any time).
One way of thinking about this would be to use the 64 different ways to separately characterize the “Conversion Value”. For example, we could choose to map the different states within the app — i.e. map each state to an achieved level within a game.
000000 = Level 0
000001 = Level 1
000010 = Level 2
and so on
We could also use the 64 “states” to map cumulative revenue driven by the user (we can map up to $63 in this example with 000000 being a non-payer)
000000 = Spent $0
000001 = Spent $1
000010 = Spent $2
The Conversion Value, however, has a 24-hour timer attached to it. If it’s not updated within 24 hours, Apple reports the last Conversion Value sent by the app. Therefore, we want the user to be able to reach the highest “Conversion Value” within the allotted time of 24 hours. In the example, if the player can’t reach level 63 within 24 hours or can’t spend $63, then a developer may want to rethink how they describe Conversion Value.
Using bits to encode “time” into the Conversion Value
Another way to think about how to use Conversion Value is by splitting up the bits. We can use some bits to represent “time” and some to represent other “states” (e.g. levels or revenue).
See below for an example using 2 bits to measure time, and 4 bits for other types of “state”.
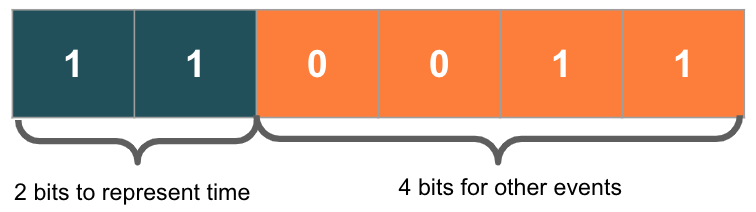
We’ve described on the below left-hand side table, an example of 2-bit values and how they are used to represent time. The 0’s and 1’s are shown turned off or on in all combinations, 00, 01, 10, 11. We can then map a “state” to each of these combinations — let’s say we map the number of days: 0, 1, 2, 3.
Now let’s look below at the right-hand side table for an example of a 4-bit value to complete our “6-bit value”. In the example, we’ve written out all the various ways (16 combinations) to write 0 and 1 with 4 numbers to play with. Let’s take each combination as an associated range of predicted LTV’s (pLTV) of $0 to $10,000. We’ve made up some examples of ranges for each of the 4-bit values.
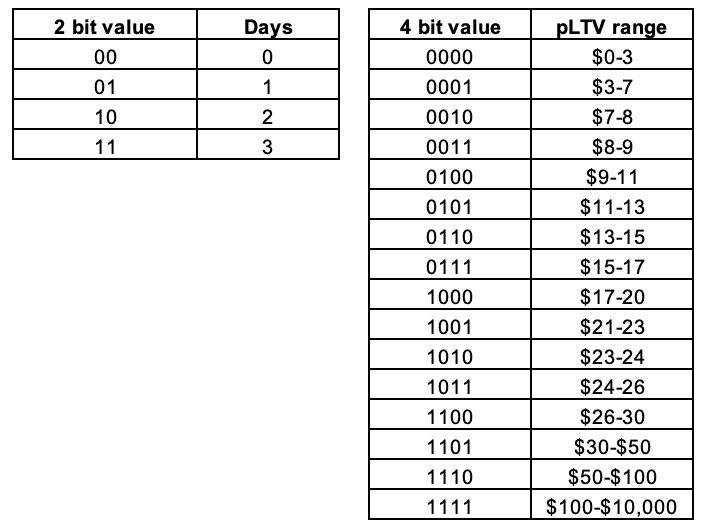
If we combine a 2-bit value with a 4-bit value we get a 6-bit value. This allows us to encode the number of days (the 2-bit value) as well as a pLTV range (the 4-bit value).
For example, if we wanted to describe a user who was 3 days old and had a pLTV of $200, we’d use 11 from the left-hand table (above) and 1111 from the right-hand table (above).
Other combinations and uses of the 6-bit value
In the example above, we’ve chosen to encode “time” as 2 bits and pLTV into the 4-bit values. However, we could choose to use a different number of bits for time and the remaining bits for other information.
Time: Instead of using 2 bits we could use 1, 3, 4, or 5 bits. This would give us a maximum of 1, 7, 15, or 31 days to wait to describe a user.

Ideally, we wouldn’t want to wait 31 days to report post-install data against a campaign as that would be far too long after the install was delivered for this information to be useful in optimizing the campaign. It’s likely the longest we’d want to wait after the install would be 7 days but more likely 1 or 3 days (1 or 2 bits) is the best use of representing time in the 6-bit value.
Remaining bits: We could use the remaining bits to describe more simplistic “states”, for example:
- Revenue: Encode different ranges of cumulative IAP/ad revenue that the user has generated in the app
- Retention: Encode the retention rate of the user. For this, the user needs to open the app over multiple days.
- In-app events: Encode a series of in-app events that the user completed
7. How does SKAdNetwork’s Conversion Value timer mechanism work?
Apple supports a timer mechanism within the SKAdNetwork framework to enable app developers to collect some post-install data once a user has been acquired via an SKAdNetwork advertising campaign.
Advertiser setup
Before being able to use SKAdNetwork’s functionality, the advertiser needs to set up the framework so that Apple gets notified:
- Every time an app install occurs
- Every time a user completes one of the Conversion Value “states” within the app
A. Let’s take the example of App B as a game and Conversion Value is levels within the game. A 6-bit value of 1’s and 0’s has 64 different combinations so we can map levels from 0-63 (because level 0 is 000000).
B. Apple is notified via the SKAdNetwork framework within App B every time a user completes a level via the associated Conversion Value (the 0’s and 1’s).
C. With this, Apple is able to track the user’s Conversion Value progression as they complete more levels.
How the timer works:
1. Ad network A shows an ad for App B
2. User X clicks on the ad for App B
3. Using SKAdNetwork tracking capabilities, Apple is able to track that User X clicked on an ad for App B as well as the campaign ID and ad network that click came from
4. User X installs App B from the App Store
5. At the point at which User X opens App B:
-
- Ad Network A and the advertiser don’t know that User X came from an Ad Network A advertising campaign
- Apple knows which campaign and Ad Network (A) drove the install. This is because Apple is notified when every new app install occurs.
- The Conversion Value at the time of install for User X is 000000.
6. Once User X opens App B, SKAdNetwork (Apple) starts a 24-hour rolling timer. For the advertiser to be able to track when a user completes one of the next “states” of the Conversion Value, they need to complete the action within 24 hours after the install.
7. Let’s use the example where App B is a game and “states” of the Conversion Value are completed levels within Game B from 0-63 (because level 0 is 000000).
8. To be able to track User X completing Level 1, we need the user to complete the level within 24 hours. If they don’t, then we can’t track the user’s progression within App B any further because the 24-hour timer has run out.
If the timer runs out, then Apple waits a random amount of time, between 0-24 hours, before notifying Ad Network A that:
- A. An install occurred, which campaign it came from, and what app drove the install
- B. The highest Conversion Value that the anonymous user achieved. If the user didn’t reach Level 1 within 24 hours, the Conversion Value would be 000000.
9. If the user completes Level 1 within 24 hours of the install, then because Apple is notified every time every user completes a level, they know the Conversion Value for User X is now 000001.
10. At this point, the 24-hour rolling timer resets back to 0 and another 24-hour rolling timer begins. The timer can be updated 63 times in total.
How can advertisers use the timer in a more intelligent way?
We’ve described a simple way to use Conversion Value to track the levels a user completes within a game. However, this approach raises a key challenge. In this example, we have no consistent way to understand when an install occurred as players of the game will complete levels at different speeds and SKAdnNetwork doesn’t include any time/date stamp for the install. It’s crucial for both the advertiser ad network to know when the install occurred (and the associated Conversion Value) to enable them to optimize campaigns.
Therefore, it’s important to introduce a consistent method to report back the time of an install. We previously discussed using the Conversion Value to include the number of days after the user has opened the app. We can combine this approach with the 24-hour timer mechanism that exists in SKAdNetwork to ensure that all install data (plus associated Conversion Value) is reported at a consistent time period after the install. This means it’s crucial to always use between 1-3 bits of the ConversionValue to account for “time”. With this, we control when the Conversion Value is sent.
8. Why do advertisers have to use a probabilistic attribution model? Why can’t I just use Conversion Value to optimize campaigns?
Optimizing only to Conversion Value is another possible approach to optimizing campaigns. In this case, the advertiser wouldn’t model the predicted revenue that campaign drove, but only model the long-term ROAS of users/cohorts as a function of Conversion Value, either by encoding pLTV directly into Conversion Value or by building a model that maps Conversion Value to LTV at some time horizon. The model can be built using historical user data as long as the definition of Conversion Value is consistent for those users.
Ideally, the Conversion Value (whether based on predicted LTV or some other behavioral signal) acts as an early signal ad networks can optimize against. Later evaluations of ROAS for particular campaigns or channels should incorporate more matured behavioral data, as opposed to operating on just an early pLTV bucket or conversion event. This is where probabilistic attribution becomes critical so that advertisers can properly distribute their most up-to-date revenue projections amongst campaigns and channels.
The diagram below shows the various datasets available to advertisers in the ATT era:
- SKAdNetwork postbacks which deliver measurements of installs and Conversion Values associated with campaigns/source apps but are fully anonymized and don’t have any associated user IDs
- Traditional network-reported metrics (mainly spend, impressions, and installs)
- Anonymized (user-level) behavioral data, which will continue to be a very rich dataset encompassing all users’ behavior throughout their lifetime of using that app
- Deterministic attribution from MMPs: This data is missing from the below diagram. This data isn’t used in the probabilistic attribution model, apart from assigning a 100% probability to the opt-in installs and reducing the number of installs necessary to assign a campaign membership probability.
- Simply optimizing against Conversion Value postbacks neglects valuable data that comes in as cohorts mature and allow for updated LTV projections. A probabilistic attribution solution should be built to leverage all datasets as best as possible, to provide the most accurate estimates of asset-level ROAS.
![]()
9. Why is a top-down (MMM) approach to iOS 14+ attribution suboptimal?
Another alternative measurement approach on iOS 14 is a top-down model or a “media mix model” (MMM). A media mix model is an alternative advertising measurement approach to last-click attribution and uses probabilistic methods versus the deterministic model of the last click. In the ATT era of mobile advertising, the model would attempt to quantify the incremental return on ad spend (ROAS) from any given channel within the context of a portfolio of channels. A critical piece of this model would be the inclusion of the incremental revenue from organic installs as a result of paid user acquisition.
When attempting to quantify the incremental returns of any given channel, our first task would be to model the absolute returns of that channel. Although SKAdNetwork offers limited capabilities, it does report anonymous install counts and Conversion Value. Both pieces of data are sufficient and critical to model the predicted returns from any channel. Due to the availability of this data at the campaign level, it’s better to take the bottom-up approach than to throw out critical data that can help us model channel or campaign performance. It’s, therefore, optimal to continue executing a bottom-up approach to attribution than to move wholly to a media mix model.
That said, there are use cases for an MMM-like approach to model incremental organic installs and revenue from paid acquisition (organic lift) at the channel level. But these approaches often run into data sparsity issues for smaller channels. It’s unlikely that they can easily be extended to the campaign level.
In short, MMMs ignore valuable signals that can build a bottom-up view of performance, such as SKAdNetwork Conversion Values that give some idea of ROI at the campaign or channel level. Additionally, MMM as a statistical approach needs a minimum install volume that’s typically unavailable at the campaign level.
10. Why is last-click attribution here to stay?
Last-click attribution only rewards the last campaign for the app install but it’s likely that a user viewed or clicked on more ads than just the last ad they clicked before they installed the app. Self-attributing networks (SANs) don’t report user-level click or view data to MMPs unless they wish to claim credit for the install. This gives an incomplete view of the user’s journey to install and makes multi-touch attribution on mobile impossible. SKAdNetwork further compounds this problem. Not only is SKAdnetwork a last-click attribution model, but it also removes the ability to track impressions across ads and ad networks, making it impossible to collect the necessary data to perform multi-touch attribution. At present, the best we can hope for is a statistical estimate of last-click attribution.
11. What is fingerprinting and why is it flawed?
Fingerprinting is a solution provided by MMPs where the MMP SDK is unable to access the device IDFA. This is either because the ad network can’t access the IDFA (i.e if the ad is on mobile web), or because the user has restricted access to the IDFA through Limit Ad Tracking (LAT).
MMPs create an ID when a user clicks on a mobile ad using device data such as IP address, device name, device type, OS version, and mobile carrier. When the app opens for the first time after install, the MMP generates a corresponding fingerprint ID using the same data.
Also Read: Probabilistic Attribution Does Not Equal Fingerprinting — Here’s How
A long enough list of device-level attributes can theoretically ensure that no two devices get the same fingerprint ID and are thus deterministically distinguishable across platforms. In practice, fingerprinting is unreliable since IP addresses change frequently as the end-user IP address changes based on moving around in the world.
Fingerprinting is fundamentally flawed on iOS 14+ for several reasons:
- Outputting a deterministic output from non-personally identifiable information is impossible. There’s no way to predict with 100% certainty that a campaign drove an install using fingerprinting methodologies.
- Rounding a probability up to 100% loses important data. When we round a prediction that a user to a campaign to 100% we lose important data about other campaigns that may have driven that install. This revenue should be accounted for if one wants to properly predict campaign performance.
- Accuracy rates deteriorate significantly over time using fingerprinting. This article from Kochava states the accuracy of attribution with a click-to-install time of 3-24 hours as ~30%. Fingerprinting is really only viable for click-to-install times under 10 minutes.
- Lastly, and most importantly, fingerprinting has been explicitly restricted by Apple as part of their iOS 14 announcement without first gaining permission from the end-user through ATT
![]()
12. Why advertisers can’t use deterministic data to infer campaign performance on iOS 14+
It may be tempting to use deterministic data from a campaign to infer the performance of the whole campaign or future campaigns.
This approach has two fundamental issues:
- Data from deterministic attribution prior to the launch of iOS 14 quickly became stale after the release of iOS 14. Using this data for any form of machine learning (supervised) model will result in a model that deteriorates in performance over time.
- To effectively deterministically attribute using IDFA, access to the identifier needs to be granted in both the publisher and the advertiser app. Therefore, if the end-user gives permission for Facebook to access their IDFA but the user doesn’t give permission to access their IDFA within an app that Facebook is promoting, then deterministic attribution can’t be completed.
- Furthermore, using this data to derive campaign performance is suboptimal. Users who opt in to share their IDFA aren’t a random sample of users and therefore the data collected through deterministic attribution will be a biased representation of the campaign as a whole.
13. Why is deterministic attribution still useful on iOS 14+? Why can’t I just use SKAdNetwork?
Apple provided SKAdNetwork with iOS 14 as an attribution solution and therefore, because of how that technology works, all attribution through SKAdNetwork will be probabilistic.
There are two ways to handle deterministic attribution:
- Use it as an input to a probabilistic attribution model, updating attribution probabilities for users who didn’t consent to the deterministic attribution. The uplift from this is highly dependent on the rate at which users consent; with little or no consent, it will not significantly augment the model.
- Ignore it and rely solely on SkAdNetwork signals for probabilistic attribution. In this case, the deterministic attribution can be used as a fallback, i.e. checking that a user attributed to Campaign A has a high probability of originating from Campaign A from the probabilistic model.
14. Why is accurately predicting LTV more important than ever on iOS 14+?
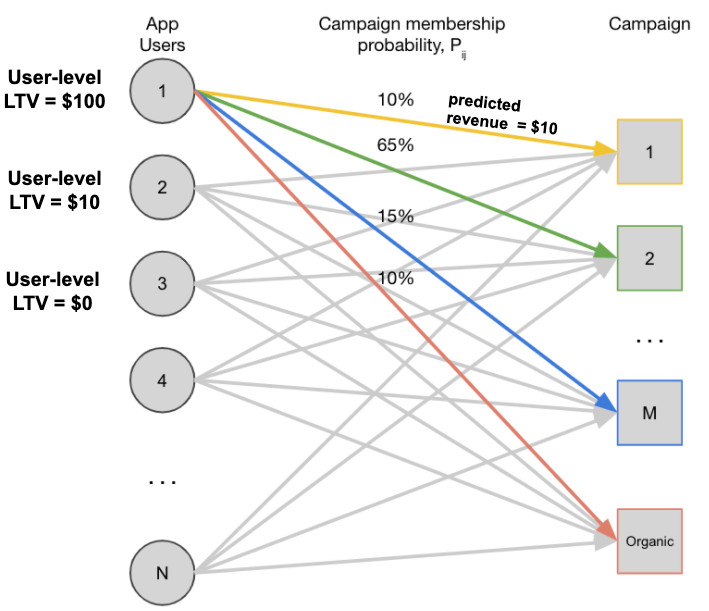
Predicting LTV and specifically predicting user-level LTV has never been more important. User-level LTV predictions have two core uses on iOS 14+ that are fundamental to accurately predicting campaign performance on iOS 14+:
- Probabilistic Attribution: User-level LTV predictions ensure the appropriate predicted revenue contribution from each install can be allocated to the correct campaign based on the campaign membership probability. In the example above, the user-level LTV for App User 1 is $100 and the user had a 10% probability of originating from Campaign 1. In this case, the predicted revenue is $10. Without a user-level LTV model, it would be impossible to accurately predict future revenue from Campaign 1. Furthermore, LTV can be updated over time as more behavioral data (revenue, in-app events) is collected. This means the ROAS of the campaign can be updated as the cohort matures. This would be impossible without a user-level LTV model and the campaign ROAS would be static at the time the Conversion Value was sent.
- Conversion Value: User-level predicted LTV is essential for effective use of Conversion Value. Using any other value than pLTV as the Conversion Value is suboptimal as one only achieves a partial understanding of the current and future performance of the campaign.
Learn more about AlgoLift by Vungle’s measurement solutions that solve for Apple’s privacy changes by contacting us below.